
Apside & S3NS : Pionniers du Cloud de Confiance
Apside, Pionnier du Cloud de Confiance & des services Google Cloud (Early Adopter)
Chez Apside, l’innovation et l’adoption précoce de technologies de pointe sont au cœur de notre stratégie. En tant qu’Early Adopter du Cloud de Confiance de S3NS, nous avons eu l’opportunité de tester les services Google Cloud Platform dans un environnement souverain alliant sécurité, scalabilité et performance.
Pourquoi S3NS ?
Pour répondre aux enjeux de souveraineté et de conformité de nos clients les plus sensibles, nous avons participé dès début 2025 au programme d’adoption anticipé de S3NS, le cloud de confiance co-développé par Google Cloud et Thalès. Cette immersion nous a permis d’approfondir notre expertise et de valider des cas d’usage réels dans un cadre sécurisé.
Notre Démonstrateur : traitement des données d’assurance sensibles
Cas d’usage du démonstrateur
Simuler la migration et l’exploitation de données sensibles issues du secteur assurance, depuis leur génération on-premise jusqu’à leur visualisation dans le cloud, tout en garantissant traçabilité, sécurité et anonymisation.
Architecture Technique Résumée
- Terraform pour l’infrastructure (GCP, Kubernetes, Kafka, Storage…)
- Python pour la synchronisation, la publication Kafka et la supervision
- Kafka comme bus d’événements
- Prometheus/Grafana pour la supervision
L’objectif de cet article complet est de fournir un guide reproductible, avec des extraits de code concrets, pour déployer et exploiter ce type d’architecture.
Notre architecture sur S3NS
Dans notre cas d’usage, en tant que DSI d’une société d’assurance, les systèmes <on-premise> ont été historiquement déployés de cette manière pour garder la maitrise des données sensibles. Mais face à la croissance des volumes, ainsi que la nécessité d’analyser rapidement les données et à la demande de nouveaux services, la scalabilité du cloud devient incontournable.
Le défi est donc de migrer et exploiter ces données sensibles dans le cloud, sans compromis sur la sécurité ni la conformité.
Notre POC simule un flux de traitement de migration de données d’assurance, depuis sa collecte sur site jusqu’à la visualisation, en passant par le stockage et l’analyse avancée.
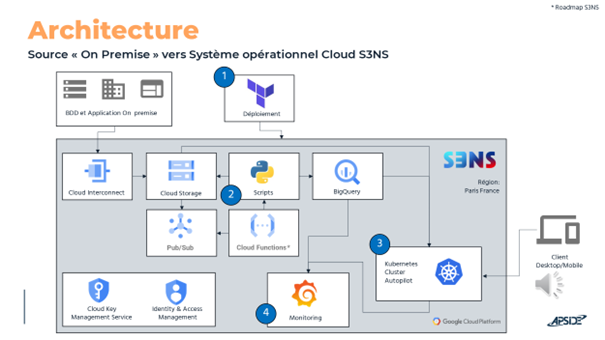
Composants clés :
L’infrastructure est décrite et provisionnée via Terraform, permettant la gestion déclarative des ressources (réseaux, IAM, KMS, GKE autopilot, BigQuery, stockage). Les workloads applicatifs sont orchestrés sur Kubernetes (GKEA), avec une séparation stricte des namespaces et des secrets pour l’isolation.
- Provisioning : Modules Terraform pour GKE, BigQuery, KMS, IAM, stockage.
- Sécurité : Utilisation de KMS pour le chiffrement qui rajoute une couche de sécurité mais pas nécessaire en EAP, IAM pour le contrôle d’accès, secrets Kubernetes pour les credentials et un VPC Service Control.
- Observabilité : Prometheus pour la collecte de métriques, Grafana pour la visualisation, intégration native avec les workloads Python.
Prérequis : configuration d’un workforce Identity Federation (WIF) via SAML ou OIDC.
#Export variables :
AUDIENCE=locations/global/workforcePools/$WorkforcePool/providers/$Provider
UNIVERSE_WEB_DOMAIN=”cloud.s3nscloud.fr”
UNIVERSE_API_DOMAIN=”s3nsapis.fr”
gcloud iam workforce-pools create-login-config $AUDIENCE –universe-cloud-web-domain=”$UNIVERSE_WEB_DOMAIN” –universe-domain=”$UNIVERSE_API_DOMAIN” –output-file=”$home_repo/wif-login-config.json”
gcloud auth list
output
Déploiement de la Landing Zone via Terraform :
La landing zone S3NS a été déployée automatiquement avec Terraform, en utilisant les providers et APIs spécifiques à S3NS (ex : endpoints `s3nsapis.fr`).
Particularités S3NS :
- Gestion des identités et accès (IAM) adaptée à la souveraineté.
- Utilisation de KMS S3NS pour le chiffrement des données.
- Déploiement de ressources (GKE, BigQuery, Storage, etc.) dans une région française
- Configuration des providers Terraform pour pointer vers les APIs S3NS et gérer les credentials de service account de confiance.
## Everytime to login with ADC also – Required to run Terraform modules or impersonate using SA
gcloud auth application-default login –login-config=wif-login-config.json
Backend & provider :

On-premise :
Les experts Apside ont simulé un environnement local (on-prem) pour générer des données d’assurance (clients, contrats, etc.) à l’aide de scripts Python. Ces données sont stockées dans des fichiers CSV dans un répertoire local (`./data_onprem`).
Ce choix permet de reproduire un contexte réel où les données sensibles sont d’abord créées et stockées sur site, avant toute migration vers le cloud.
Script de migration/ingestion : synch-to-cloud.py load-to-bq.py
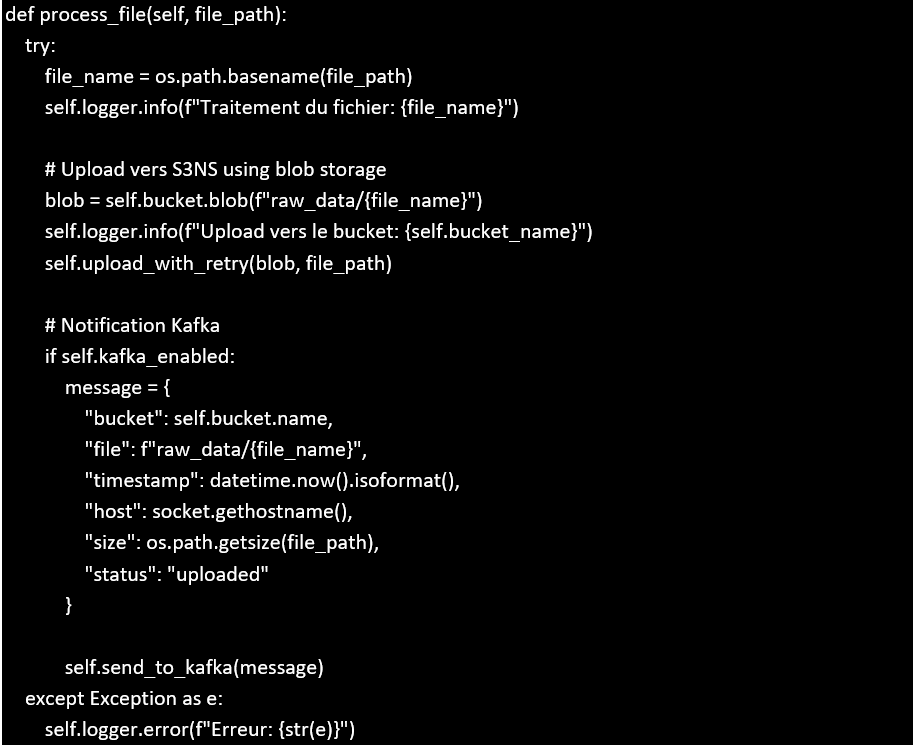
Pour migrer les données depuis on-prem vers le cloud, les Apsidiens ont développé des scripts Python :
– synch-to-cloud.py : surveille le répertoire local, détecte les nouveaux fichiers et les transfère vers Cloud Storage S3NS.
– `load-to-bq.py` : charge les fichiers depuis Cloud Storage vers BigQuery pour analyse.
Ils ont contourné l’absence de Cloud Functions S3NS (qui arriveront prochainement sur la plateforme) en orchestrant ces étapes via des scripts et des jobs Kubernetes, tout en assurant la traçabilité et la robustesse du pipeline.
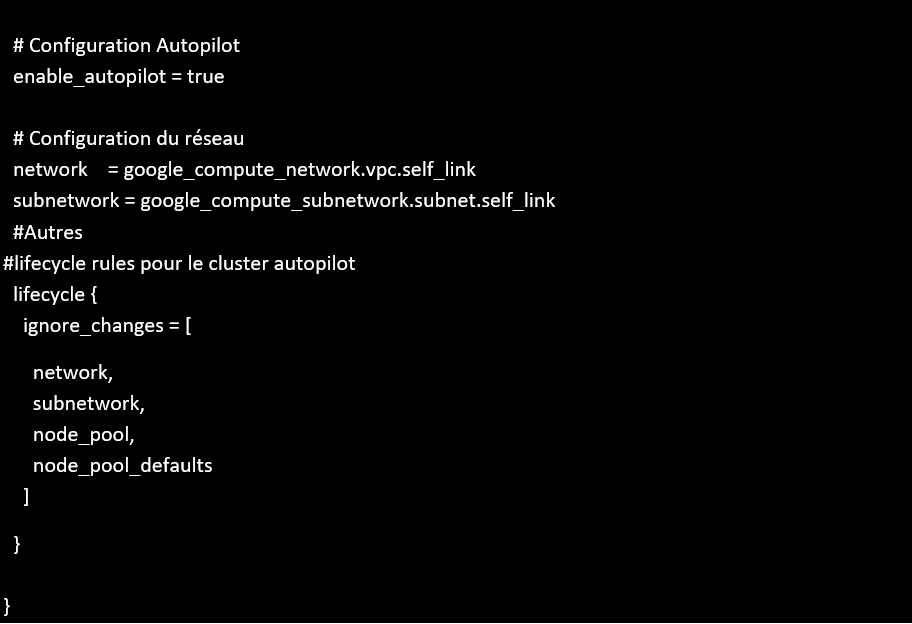
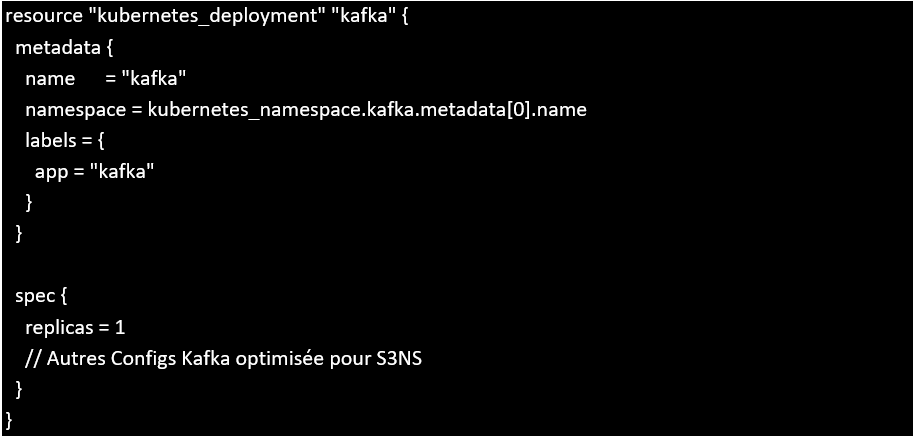
Infrastructure Kafka dans GKE Autopilot :
Pour simuler un bus d’événements cloud-native, une stack Kafka a été déployée sur GKE Autopilot (cluster Kubernetes managé S3NS, le seul disponible dans l’EAP).

Kafka permet de bufferiser, distribuer et traiter les flux de données en temps réel, tout en restant dans l’environnement de confiance S3NS.
Génération et anonymisation
Les données clients sont générées via des scripts Python notamment avec les librairies Python FAKER, puis anonymisées selon des règles configurables (hash, masquage, suppression). L’anonymisation est réalisée en streaming ou batch, avec suivi des lignes traitées et stockage des résultats dans BigQuery.
Ingestion et Traitement avec Bigquery
Les fichiers CSV sont chargés dans GCS, puis importés dans BigQuery via des jobs Python instrumentés (prometheus_client).
Anonymisation incrémentale
Avant l’analyse, un service d’anonymisation (Python) traite les données pour masquer les informations sensibles (noms, emails, etc.), en appliquant des règles d’anonymisation (hash sha256 avec du bruit, masquage, etc.).
Ce composant garantit que seules des données anonymisées sont exploitées pour l’analyse, en conformité avec les exigences réglementaires.
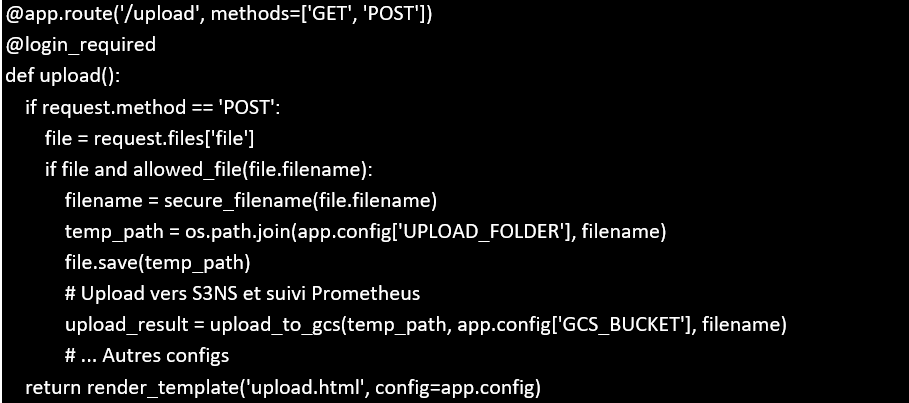
Application Flask déployée dans le GKE Autopilot :
Au cœur de notre POC, les experts ont développé une application Flask qui sert d’interface utilisateur pour la gestion, l’upload et la visualisation des données d’assurance migrées.
Architecture & sécurité :
L’application est conteneurisée (Docker) et déployée sur Kubernetes. Elle intègre :
- Authentification et gestion des rôles : via Flask-Login et des modèles SQLAlchemy
- Sécurité avancée
- Formulaires robustes pour l’upload de fichiers dans GCS, la saisie de données d’assurances, intégré par la suite dans Bigquery.

Fonctionnalités principales :
- Upload : les utilisateurs peuvent déposer des fichiers de données d’assurance, qui sont ensuite stockés dans un bucket S3NS et traités par le pipeline.
- Visualisation : les données clients sont consultables via la connexion à Bigquery.
- Admin : Gestion des users, rôles et accès au dashboard.
Data visualisation :
Pour compléter notre chaine de traitement, un choix a été arbitré afin d’utiliser Grafana, qui est partenaire d’Apside dans le domaine, et leader dans le monde de la data-vizualisation afin de monitorer :
- Les métriques de performance système
- Les tendances dans les données de l’assurance
- Les alertes en cas d’anomalies.

Conclusion
Notre engagement en tant qu’Early Adopter de S3NS nous a permis :
- D’acquérir une maîtrise concrète des services Google Cloud Platform en environnement souverain.
- De collaborer étroitement avec les équipes S3NS, très réactives et à l’écoute de nos retours.
- D’anticiper les futures évolutions, notamment les composants IA et l’arrivée de modèles Mistral sur la plateforme.










