
Google I/O Connect 2025
Le 25 juin 2025, Google organisait son I/O Connect à Berlin. Une occasion de découvrir les dernières annonces produits, les tendances IA du moment, et d’échanger avec une communauté riche et inspirante.
A l’image de l’évolution de l’écosystème technologique ces dernières années, la majorité des annonces et démonstrations étaient centrées sur l’Intelligence Artificielle Générative.
Ce récapitulatif se concentre sur les nouveautés liées aux modèles d’IA générative. Un second article abordera les agents, les frameworks (ADK) et protocoles associés (A2A) annoncés également par Google.
Des modèles en nombre… et en puissance
Un des faits marquants de cette édition de l’I/O Connect est la diversité des domaines couverts par les modèles d’intelligence artificielle générative développés par Google.
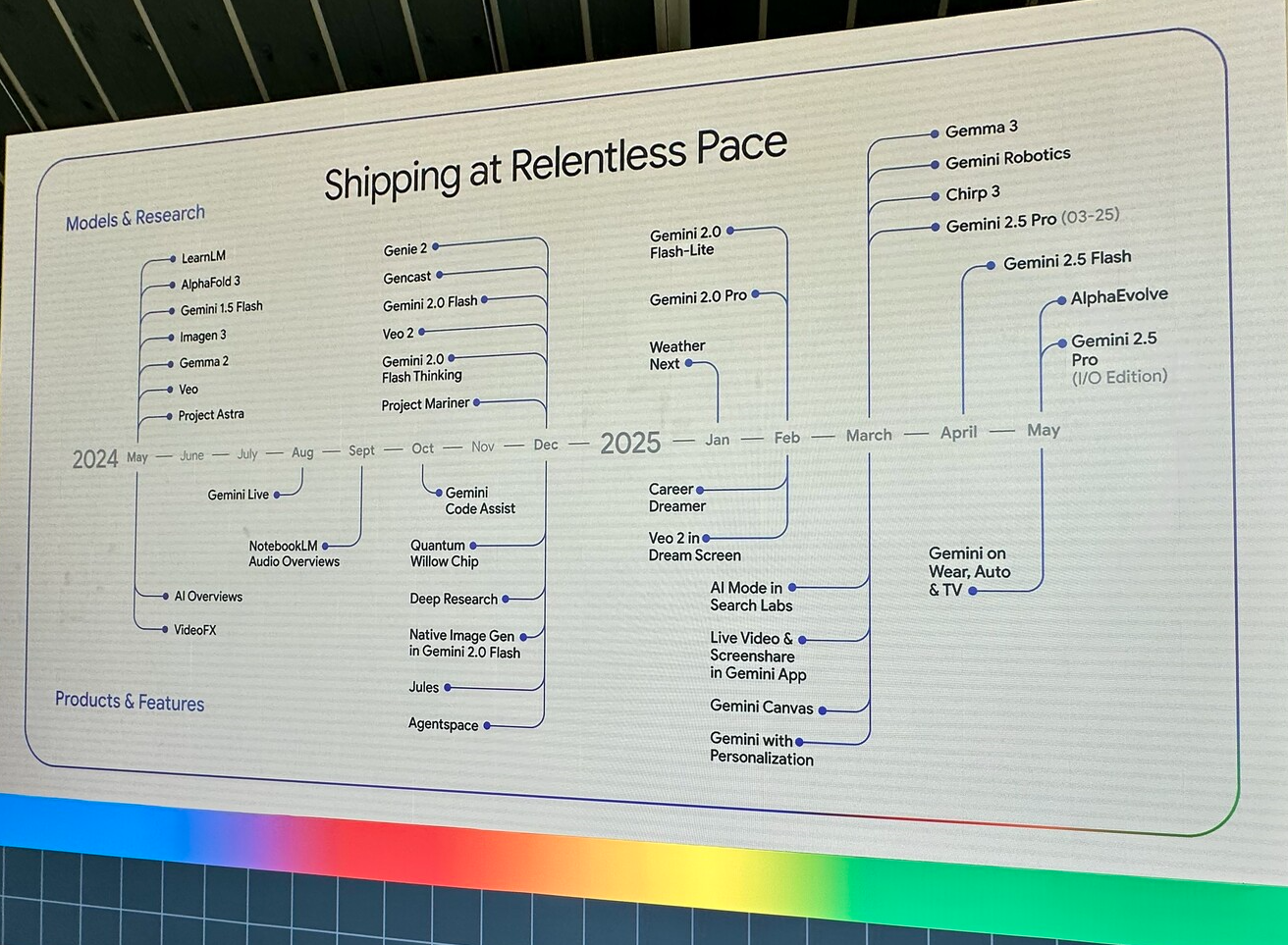
Lors de l’I/O Connect, Gemini est apparu sur le devant de la scène mais ce n’était pas le seul modèle présenté lors de cet événement puisqu’étaient également présentés les nouvelles déclinaisons des modèles Gemma, Veo et Imagen.
Les modèles généraux et multi-modaux
Plusieurs présentations lors de la journée ont montré les capacités et les domaines couverts par les modèles frontière de Google, Gemini.

Les modèles Gemini s’illustrent particulièrement par leur capacité avancée à traiter différentes modalités (images, texte/code, vidéo et audio), et ceci de façon native.
De plus, la dernière version 2.5 des modèles Gemini constitue une famille de modèles dit de “réflexion”, c’est à dire qu’il offrent au moment de la prédiction de la réponse à une demande utilisateur, la possibilité d’inclure une phase initiale de réflexion pendant laquelle le modèle va écrire des courants de pensées pour raisonner sur la requête utilisateur.
Une fois cette phase initiale terminée, le modèle continuera sa prédiction de réponse à l’utilisateur en s’appuyant à la fois sur le contexte initialement présent ainsi que sur sa chaîne de réflexion.

Gemini : multi-modalité, raisonnement et performance
Plusieurs versions de Gemini sont disponibles et répondent à des cas d’usages différents :
- Gemini 2.5 Flash Lite : Le modèle le plus léger de la famille Gemini, particulièrement adapté pour les tâches de grand volume nécessitant d’optimiser les coûts ($0.1 pour 1M tokens en entrée et $0.4 pour 1M en sortie). Il s’agit d’un modèle dont les inférences sont très rapides mais qui échange la rapidité contre une performance moins élevé que les autres modèles de la famille.
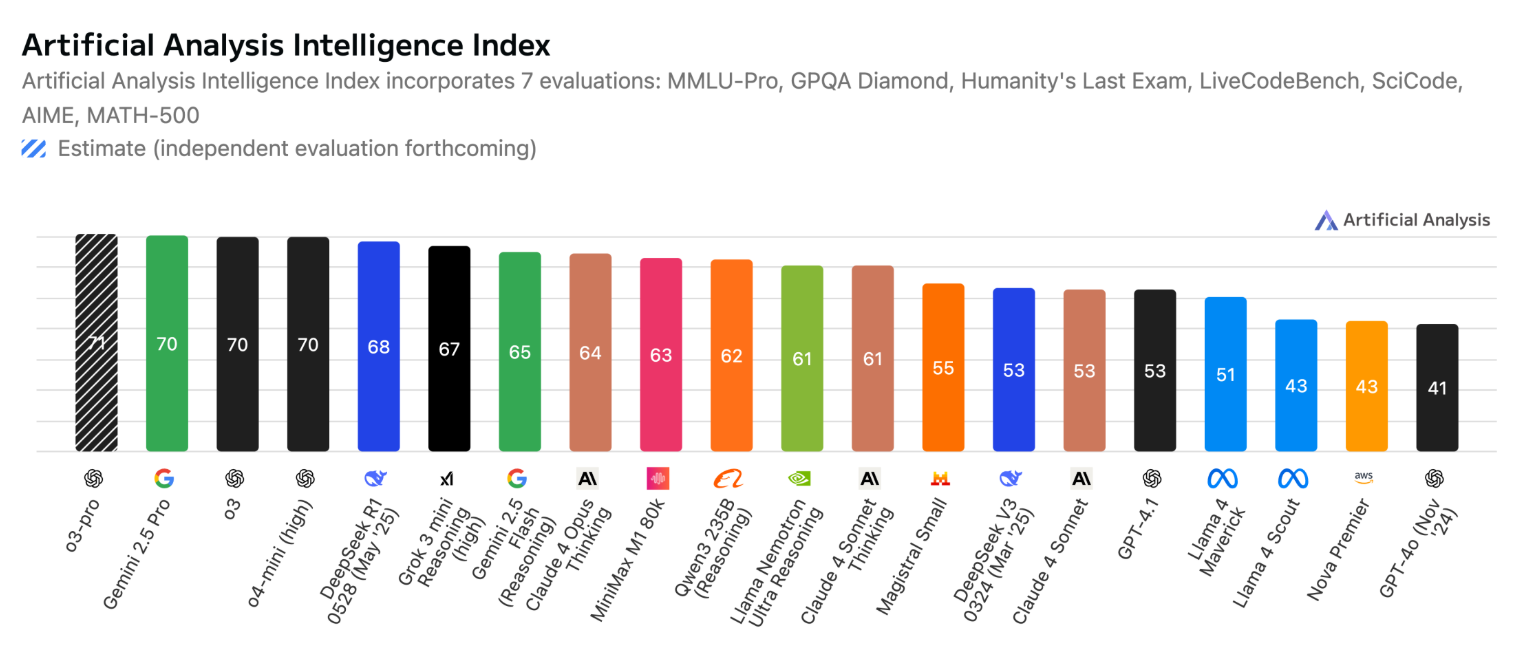
- Gemini 2.5 Flash : Il s’agit du modèle intermédiaire qui offre un compromis entre performance et rapidité pour un coût maîtrisé ($0.3 pour 1M de tokens en entrée et $2.5 pour 1M en sortie). Ce modèle est indiqué pour les tâches quotidiennes mais est affiché tout de même parmi les modèles les plus performants dans différents benchmarks sur artificial analysis.
- Gemini 2.5 Pro : Considéré comme l’un des meilleurs modèles existant sur le marché (et qui ressort particulièrement dans différents benchmarks également), ce modèle est le modèle majeur de la famille Gemini qui offre les meilleures performances, faisant un compromis sur la rapidité du modèle. Malgré sa position parmi les modèles les plus performants, Gemini 2.5 Pro reste un modèle compétitif puisque sa tarification se positionne à $1.25 pour 1M de tokens en entrée et $10 pour 1M en sortie.
Gemma et ses déclinaisons
Afin de répondre aux enjeux des projets les plus contraints, Google a créé, début 2024, la famille de modèles open source nommée Gemma qui vise à proposer des modèles libre d’utilisation en environnement restreint, permettant alors d’envisager des scenarios d’usage d’IA générative au plus proche des utilisateurs grâce à des modèles dont la taille permet l’exécution sur un ordinateur portable, voir des machines moins puissantes encore.
Après les deux premières versions de Gemma publiées en 2024, Google revient avec une nouvelle version de son modèle open-source et de nouvelles déclinaisons, montrant le potentiel de cette famille de modèle lorsqu’une spécialisation y est appliquée.
- Gemma 3 : La nouvelle mouture du modèle Gemma, pour la première fois en capacité des images en plus du texte, disponible dans différentes tailles (1b, 4b, 12b et 27b) pour répondre aux exigences des environnements les plus restreints tout en offrant des capacités de raisonnements multi-modaux. Lors de la Google I/O Connect 2025, une démonstration montrait de très bonne capacités de restitution de tableaux en json depuis une image en utilisant le modèle Gemma 3 4b au format MLX, ce qui présage des performances intéressantes pour les modèles Gemma 3 de taille supérieur.
- Gemma 3n : Version optimisée du modèle Gemma 3 destinée à l’exécution dans des environnements très restreints permettant le traitement de texte, image, son et vidéo directement depuis un smartphone par exemple, garantissant ainsi la confidentialité des données traitées dans une application exploitant des modèles d’IA Générative. Ce type d’initiative (et l’équivalent proposé par Apple) laisse entrevoir un avenir où les traitements courants nécessitant un modèle d’IA Générative s’exécuteront directement sur les périphériques des utilisateurs finaux plutôt que solliciter systématiquement des ressources dans le cloud.
- Dolphin Gemma : Une variante plutôt étonnante des modèles Gemma, destinée à comprendre et établir une communication avec les dophins en exploitant des vocalisations pour estimer un vocabulaire commun.
- MedGemma : Une version de Gemma 3 spécialisée dans la classification et l’interprétation d’images médicales ainsi que dans la réponse aux questions médicales.

Les modèles Gemma étant généralistes, ils sont appropriés pour une grande variété de tâches grâce à une fenêtre de contexte conséquente de 128000 tokens, tout en permettant un usage hors ligne, garantissant ainsi la confidentialité des données. Les modèles Gemma 3 sont également simple à personnaliser pour une application plus proche du contexte d’utilisation.
Une distinction fondamentale par rapport aux modèles Gemini est à noter cependant, les modèles Gemma ne sont pas des modèles de “raisonnement” et peuvent apparaître comme étant moins performants dans les différents benchmarks. Il convient de comprendre alors que si il est nécessaire de bénéficier d’étapes de raisonnement, il faudra adopter un framework de raisonnement avec ces modèles.
Les générateurs de média
En plus des modèles généralistes, plusieurs modèles et outils arrivent sur le devant de la scène pour proposer la création de nouveaux contenus créatifs à la portée de tous. Lors de l’I/O Connect, plusieurs démonstrations ont montré le potentiel des modèles de génération de médias proposés par Google.
- Chirp 3 : Ce modèle de text-to-speech représente les dernières avancées en matière de génération de voix avec un niveau de réalisme impressionnant, et une communication émotionnelle qui permet d’envisager une interaction plus personnelle avec les assistant vocaux à l’avenir. L’aspect très intéressant avec ce modèle est la possibilité d’orienter par prompt l’émotion exprimée par la synthèse vocale.
- Veo 3 : Le modèle de génération de vidéo de Google a déjà fait beaucoup parler de lui. Ce modèle possède la particularité de générer les voix et bruitages associés à la scène générée. Pour encore plus de réalisme dans les scènes générées, le modèle Veo 3 a également été entraîné pour une meilleure compréhension des phénomènes physiques, réduisant les phénomènes d’incohérences physiques dans les scènes (par exemple, les éclaboussures après qu’un personnage ait plongé dans une piscine paraissent plus réalistes que ce qui pouvait être généré auparavant).
- Imagen 4 : Cette nouvelle version du modèle de génération d’image de Google apporte une nouvelle dimension de réalisme aux images générées par IA. Comparativement aux modèles concurrents, Imagen 4 est un modèle à la fois rapide et performant. Imagen 4 est disponible en 2 versions, une version standard, assez proche en termes de performances mesurée du modèle Imagen 3, et une version Ultra qui affiche une avancée significative en termes de performances mesurées en score ELO sur le benchmark genai-bench.
- Lyria RealTime : Moins connu que des alternatives telles que les modèles de Suno, Lyria est le modèle de génération de musique de Google qui s’exécute derrière sa Music AI Sandbox. Lors des annonces de cette année, Google a présenté Lyria RealTime qui ajoute la faculté de générer de la musique à la seconde, en temps réel, permettant ainsi la génération de transitions naturelles, de fond sonores génératifs et d’autres usages nécessitant l’adaptation à une bande sonore en temps réel.
Modèles pour la recherche
Au dela des modèles grand public proposés via des APIs et solutions accessibles à tous, les équipes de Google DeepMind oeuvrent à la création de modèles destinés à la recherche de pointe, permettant l’accélération de la découverte de nouvelles molécules ou bien encore la compréhension du monde et des génomes humains.
- Alpha Fold 3 : Le modèle Alpha Fold 3 n’a pas fait l’objet d’annonce à la Google I/O Connect mais mérite d’être cité comme le modèle qui peut désormais modéliser les interactions de toutes les protéines avec les molécules environnantes. Il s’agit d’une avancée scientifique majeure qui ouvre les portes sur des combinaisons nouvelles pouvant par exemple aboutir à des traitements nouveaux pour traiter des maladies pour lesquelles il n’existe aujourd’hui aucun remède.
- Alpha Genome : Un modèle nouvellement publié destiné à la compréhension du génome humain. Alpha Genome permet notamment d’estimer les impacts d’une mutation de séquence d’ADN sur un éventail de processus biologiques régulant les gènes. Il s’agit d’une avancée majeure vers la compréhension du fonctionnement du génome humain qui pourrait aboutir à la découverte de nouveaux traitements, ou à la compréhension des mécanismes sous-jacent au développement de maladies.
Conclusion
Cette édition de l’I/O Connect Berlin démontre à quel point Google continue de structurer et faire progresser l’écosystème de l’IA Générative.

Des modèles puissants comme Gemini, des solutions open source avec Gemma, des outils multimédia comme Chirp, Veo, Imagen ou Lyria, et des modèles de recherche à fort impact comme AlphaFold 3 ou Alpha Genome : la stratégie est claire, diversifiée, et ancrée dans une vision long terme de l’intelligence artificielle.
Chez Apside, ces innovations nous inspirent et viennent nourrir nos réflexions sur l’IA responsable, les modèles embarqués, et la démocratisation des outils d’IA dans des contextes industriels, souverains ou sensibles.










